

随着LLM技术应用及落地,数据库需要提高向量分析以及AI支持能力,向量数据库及向量检索等能力“异军突起”,迎来业界持续不断关注。简单来说,向量检索技术以及向量数据库能为 LLM 提供外置的记忆单元,通过提供与问题及历史答案相关联的内容,协助 LLM 返回更准确的答案。
不仅仅是LLM,向量检索与OLAP引擎也早有渊源。作为一种用于数据分析的软件,OLAP能够快速、高效处理大量数据,并提供多维度的分析功能,而向量检索则能帮助OLAP引擎进一步提升对非结构化数据的分析和检索能力。
近期,火山引擎云原生数据仓库ByteHouse推出高性能向量检索功能,通过支持多种向量检索算法以及高效的执行链路,可以支撑极大规模向量检索场景,并达到毫秒级的查询延迟。
ByteHouse团队早已关注并研究向量检索技术。据ByteHouse技术专家介绍,“当前向量数据库的发展主要是两种思路,一种是建设一个专用的向量数据库,基于Vector-centric 的思路来设计向量数据及索引的存储与资源管理策略,查询定式简单,支持数据类型有限;另一种是基于现有数据库扩展向量检索能力,在已有数据管理机制以及查询执行链路中去添加向量索引维护与查询执行逻辑。目前,两种思路互相借鉴,向完备数据库功能支持+高性能向量检索的方式发展。”
ByteHouse来源于ClickHouse,但ClickHouse存在向量索引重复读取,相似度计算冗余等问题,对于延迟要求低、并发需求高的向量检索场景可用性较弱。
基于以上的分析,ByteHouse 在向量检索能力上进行全面创新。 首先,基于 vector-centric 的思路,ByteHouse 重新构建了高效的向量检索执行链路,结合索引缓存、存储层过滤等机制,使得性能实现进一步突破。另外,为了应对不同使用场景,ByteHouse 支持了 HNSW、Flat、IVFFlat、IVFPQ 等多种常见向量索引算法。此外,新引入的向量索引支持当前的二级索引相关语义,新的执行链路也对现有距离函数进行了适配,以降低用户使用门槛和学习成本,用户可以直接用 ClickHouse 的现有语义来使用高性能的向量检索功能。
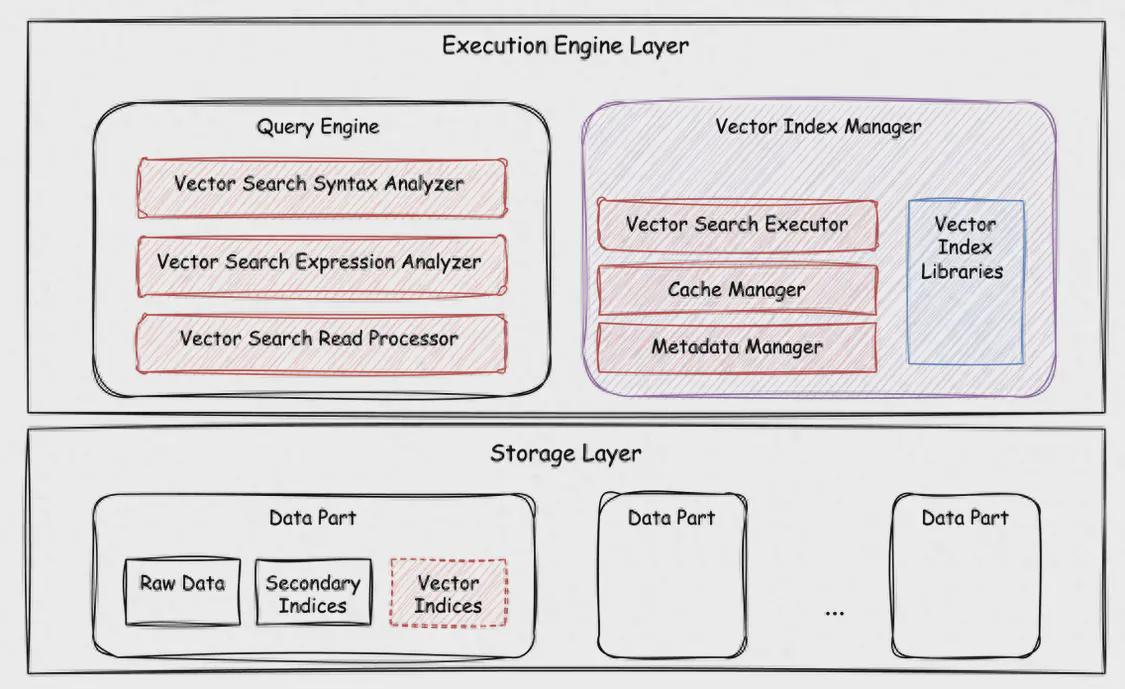
ByteHouse向量检索相关组件
在建设高性能向量检索能力过程中,ByteHouse主要克服以下三大难点:
首先,列存结构读放大问题。为了减少不必要的数据读取操作,ByteHouse在 query 执行及数据读取层都进行了相应优化,并由 HaMergeTree 以及 HaUniqueMergeTree 两种引擎的可靠方案为向量检索提供稳定性保障。其次,新写入数据以及服务重启会存在冷读的问题,导致性能波动。为此,ByteHouse 引入 preload 机制,索引构建后自动载入缓存,同时支持对过期索引自动淘汰,避免多余的资源占用。最后,由于索引构建会消耗较多的资源,为了降低构建操作对正常查询的性能影响,ByteHouse引入资源控制策略,允许用户基于使用场景动态控制索引构建使用的资源,极大减少了原有链路的开销。

基于开源软件VectorDBBench ,与 milvus 2.3.0 进行测评
(测试环境:1 node, 80 cores, 376 GB Memory)
在最终性能效果上,ByteHouse团队基于业界最新的 VectorDBBench 测试工具进行测试,在 cohere 1M 标准测试数据集上,recall 98 的情况下,可以达到与专用向量数据库相近的性能。在 recall 95 以上的情况下,QPS 可以达到 2600 以上,p99 时延在 15ms 左右,具备业界领先优势。
性能优化一直是ByteHouse核心探索方向之一,以满足不断增长的数据处理和分析需求。不仅仅是向量检索技术,通过持续的研发和创新,ByteHouse还在查询分析、数据导入等多个方面极致优化,取得了显著的性能提升,在降本增效基础上,持续帮助企业更好地在数据驱动下实现加速决策效率。
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。
- 性能持续突破!火山引擎ByteHouse上线向量检索能力(2024-01-15)
- 鸿蒙生态千帆启航仪式定档1月18日,一起见证鸿蒙进阶的新篇章(2024-01-15)
- 全球快资讯:驻马店开发区关王庙乡积极开展禁毒铲毒志愿宣传活动(2024-01-15)
- 【大圣农业】——好蛋平台构筑高品质蛋品强国梦,蛋业从业者必备!(2024-01-15)
- 文明的融合“驼铃声响——丝绸之路艺术大展”在北京民生现代美术馆开幕(2024-01-15)
- 性能持续突破!火山引擎ByteHouse上线向量检索能力(2024-01-15)
- 天天通讯!极限淬炼!AC313A开启高寒试飞(2024-01-15)
- 爱衣美创始人郭道云先生:诚信做人,脚踏实地_快资讯(2024-01-15)
- 天弘基金胡超:机遇与挑战并存 2024年海外市场谨慎乐观(2024-01-15)
- 【当前独家】数字赋能 提速增效 柯尼卡美能达为法院/律所行业注入智慧办公新动能(2024-01-15)
- 简讯:2024海豚邦持续创新创优,深圳分公司筹备处正式成立(2024-01-15)
- 鸿蒙生态千帆启航仪式定档1月18日,一起见证鸿蒙进阶的新篇章(2024-01-15)
- 一秒到家重庆分公司CEO揭秘:公司的战略、愿景与未来 当前聚焦(2024-01-15)
- 天天动态:全要素IPv6+嵌入式海洋经略算网,加速海洋科技创新(2024-01-15)
- 超巨空投,巢聚惊喜!丰巢广告连摘两大行业奖项 天天滚动(2024-01-15)
- 再获殊荣丨库斯家居荣获2023年质量标杆品牌、中国家居行业领军品牌(2024-01-15)
- 巨星传奇:明星IP与新零售的完美融合,打造商业新篇章(2024-01-15)
- 把美术创作写到民族复兴的历史上|姚冬青专访_环球观点(2024-01-15)
- 环球看点!深圳市安徽潜山商会2024迎春年会在鹏城举办(2024-01-15)
- 强者恒昌之风云际“会”|盘点恒昌的7重会员身份-前沿资讯(2024-01-15)
- 白萝卜、羊肉、雪莲养生葡萄酒……冬令进补这样吃(2024-01-15)
- A.O.史密斯"AI-LiNK智慧能源供热系统"创新领航,荣获"节能减排科技进步奖"-最新快讯(2024-01-15)
- 再获殊荣丨库斯家居荣获2023年质量标杆品牌、中国家居行业领军品牌(2024-01-15)
- 焦点热讯:羊乃牧歌羊乳粉在浙大二院临床研究课题成功启动(2024-01-15)
- 锦成餐饮:榕江牛瘪,一道凝聚民族智慧的美味佳肴|环球新资讯(2024-01-15)
- 从“新”出发主题论坛暨骑寄品牌发布会召开(2024-01-15)
- AI遇上传统文化,文心一言上央视带来跨时空访古体验(2024-01-15)
- 官宣!爱采购AI智采集IP升级发布会,1月18日全网直播 通讯(2024-01-15)
- 世界最资讯丨2024新能源汽车产业出口展览会将于明年4月举办!展会再升级(2024-01-15)
- 电影《万里茶道》中的明与暗之争逐,编剧李端正创作谈(2024-01-15)
- 【环球热闻】两天两场“知·新”主题时装秀完美收官 乔万尼女装以直营管理模式创造品牌辉煌(2024-01-15)
- 骑寄品牌发布会开幕|周末开的骑寄品牌发布会,发布了什么?(2024-01-15)
- 永倍达:创新思维,引领新零售浪潮|快讯(2024-01-15)
- 2024新能源汽车产业出口展览会将于明年4月举办!展会再升级(2024-01-15)
- 今心:人格频率学铸造企业内力堡垒(2024-01-15)
热点排行





关于我们| 客服中心| 广告服务| 建站服务| 联系我们
中国焦点日报网 版权所有 沪ICP备2022005074号-20,未经授权,请勿转载或建立镜像,违者依法必究。